What is Version space in ML
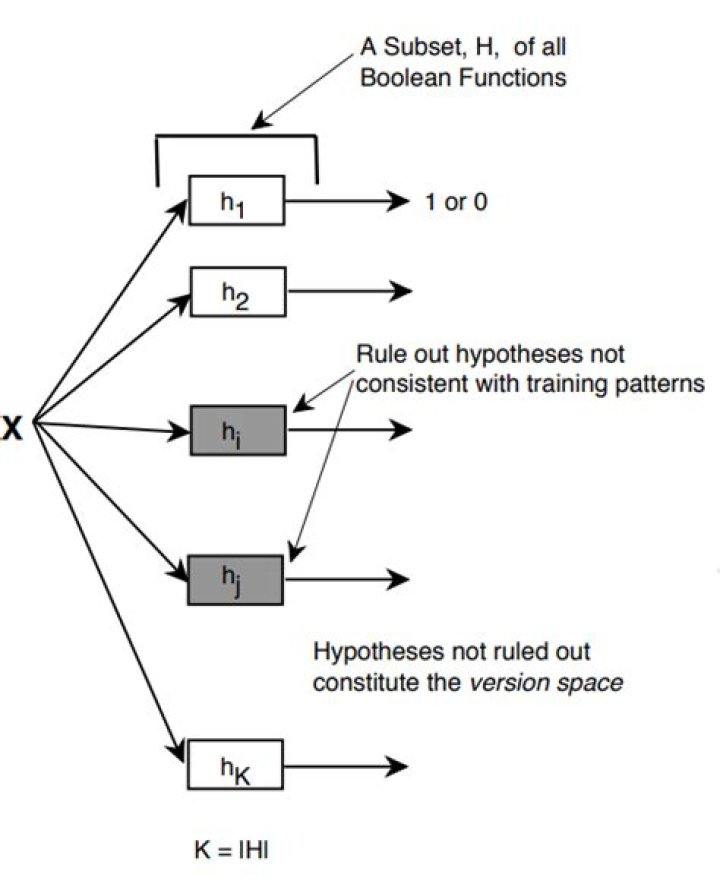
A version space is a hierarchial representation of knowledge that enables you to keep track of all the useful information supplied by a sequence of learning examples without remembering any of the examples.
What is instance space in ML?
The instance space is constructed to reveal pockets of hard and easy instances, and enables the strengths and weaknesses of individual classifiers to be identified.
What is version space in candidate elimination algorithm?
Version Space: It is intermediate of general hypothesis and Specific hypothesis. It not only just written one hypothesis but a set of all possible hypothesis based on training data-set.
What is hypothesis space instance space and version space in ML?
Instance Space: It is a subset of all possible example or instance. Version Space: The Version Space denotes VSHD (with respect to hypothesis space H and training example D) is the subset of hypothesis from H consistent with training example in D. red: Generalization of Hypothesis.What is the S boundary set of the given version space?
Note the S boundary (smallest, thin solid rectangle) and G boundaries (three other rectangles). There are three G boundaries, that is three rectangles that contain only positive points and cannot be generalized without including any negative points.
What is instance space?
An instance space is the space of all possible instances for some learning task. In attribute-value learning, the instance space is often depicted as a geometric space, one dimension corresponding to each attribute.
What are the elements of version space?
- One that contains nodes connected to overly general models, and.
- One that contains nodes connected to overly specific models.
What do you mean by hypothesis space?
Hypothesis Space (H): Hypothesis space is the set of all the possible legal hypothesis. This is the set from which the machine learning algorithm would determine the best possible (only one) which would best describe the target function or the outputs.What is version space algorithm?
Version space learning is a logical approach to machine learning, specifically binary classification. Version space learning algorithms search a predefined space of hypotheses, viewed as a set of logical sentences. Formally, the hypothesis space is a disjunction.
What is the hypothesis space?The hypothesis space used by a machine learning system is the set of all hypotheses that might possibly be returned by it. It is typically defined by a Hypothesis Language, possibly in conjunction with a Language Bias.
Article first time published onWhat is are Advantage's of locally weighted regression?
Locally weighted regression learns a linear prediction that is only good locally, since far away errors do not weigh much in comparison to local ones.
What is inductive bias in ML?
The inductive bias (also known as learning bias) of a learning algorithm is the set of assumptions that the learner uses to predict outputs of given inputs that it has not encountered. In machine learning, one aims to construct algorithms that are able to learn to predict a certain target output.
What is specific and general boundary?
The general boundary , with respect to hypothesis space and training data , is the set of maximally general members of consistent with . The specific boundary , with respect to hypothesis space and training data , is the set of minimally general (i.e., maximally specific) members of consistent with .
How does find s algorithm work?
The Find-S algorithm only considers the positive examples and eliminates negative examples. For each positive example, the algorithm checks for each attribute in the example. If the attribute value is the same as the hypothesis value, the algorithm moves on without any changes.
What is list then algorithm?
The List-Then-Eliminate Algorithm is another learning algorithm. This algorithm begins with a full Version Space (a list containing every hypothesis in H). Then for every training example, we remove every hypothesis (from the Version Space) that does not agree with the training example.
Is data mining a ML?
Data mining is used on an existing dataset (like a data warehouse) to find patterns. Machine learning, on the other hand, is trained on a ‘training’ data set, which teaches the computer how to make sense of data, and then to make predictions about new data sets.
What is a decision tree used for?
In decision analysis, a decision tree can be used to visually and explicitly represent decisions and decision making. As the name goes, it uses a tree-like model of decisions.
What is hypothesis in machine learning?
Hypothesis in Machine Learning is used when in a Supervised Machine Learning, we need to find the function that best maps input to output. This can also be called function approximation because we are approximating a target function that best maps feature to the target.
What are the different machine learning applications?
- Traffic Alerts.
- Social Media.
- Transportation and Commuting.
- Products Recommendations.
- Virtual Personal Assistants.
- Self Driving Cars.
- Dynamic Pricing.
- Google Translate.
What is decision surface in machine learning?
decision surface A (hyper) surface in a multidimensional state space that partitions the space into different regions. … Decision surfaces may be created or modified as a result of a learning process and they are frequently used in machine learning, pattern recognition, and classification systems.
What is machine learning concepts?
Machine learning is an application of artificial intelligence (AI) that provides systems the ability to automatically learn and improve from experience without being explicitly programmed. Machine learning focuses on the development of computer programs that can access data and use it to learn for themselves.
What is machine learning in Mcq?
Explanation: Machine learning is the autonomous acquisition of knowledge through the use of computer programs.
What is most general hypothesis in machine learning?
the most specific hypothesis is h0 = (⊥,⊥,…,⊥) that is satisfied by no instance. the most general hypothesis is h1 = (,,…,); every other hypothesis h satisfies h0 ≤ h ≤ h1. An example x satisfies a hypothesis h if h(x) = 1. Definition Let h be a hypothesis and let c be a concept.
What is are the problem solving methods for RL?
Three methods for reinforcement learning are 1) Value-based 2) Policy-based and Model based learning. Agent, State, Reward, Environment, Value function Model of the environment, Model based methods, are some important terms using in RL learning method.
What is null hypothesis in ML?
A null hypothesis is an initial statement claiming that there is no relationship between two measured events. A null hypothesis is a foundation of the scientific method, as scientists use experiments to accept or reject a null hypothesis based upon the relationship, or lack thereof, between two phenomena.
Why do people prefer short hypotheses?
Why Prefer Short Hypotheses? Argument: Since there are fewer short hypotheses than long ones, it is less likely that one will find a short hypothesis that coincidentally fits the training data. Problem with this argument: it can be made about many other constraints.
What is the 3 types of hypothesis?
- Simple Hypothesis. It predicts the relationship between a single dependent variable and a single independent variable.
- Complex Hypothesis. …
- Directional Hypothesis. …
- Non-directional Hypothesis. …
- Associative and Causal Hypothesis. …
- Null Hypothesis. …
- Alternative Hypothesis.
What is over fitting of model?
Overfitting is a modeling error in statistics that occurs when a function is too closely aligned to a limited set of data points. … Thus, attempting to make the model conform too closely to slightly inaccurate data can infect the model with substantial errors and reduce its predictive power.
What is the difference between loess and Lowess?
The main difference with respect to the first is that lowess allows only one predictor, whereas loess can be used to smooth multivariate data into a kind of surface. It also gives you confidence intervals. In these senses, loess is a generalization.
Why locally weighted regression is non-parametric?
Locally weighted linear regression is a supervised learning algorithm. It a non-parametric algorithm. There exists No training phase. All the work is done during the testing phase/while making predictions.
What is shrinkage method?
In statistics, shrinkage is the reduction in the effects of sampling variation. In regression analysis, a fitted relationship appears to perform less well on a new data set than on the data set used for fitting. … In this sense, shrinkage is used to regularize ill-posed inference problems.